
本课程面向有一定程序设计语言和数据库先修基础的本科生和部分致力于大数据研究方向刚入门的研究生。课程将引导学生学习如何利用大数据技术解决复杂工程问题,突出课程的创新性,进而使学生获得学习成就感,激发学习大数据领域技术的兴趣,提高理论和实际相结合的能力。
围绕大数据复合型人才培养目标,如图所示是课程的内容体系(持续更新中),九个章节包括了理论授课、拓展阅读、选修实验多个部分,定位于对选课学生“大数据观”、“大系统观”、“大工程观”的综合性、多维度的价值引领、知识传授和能力培养:
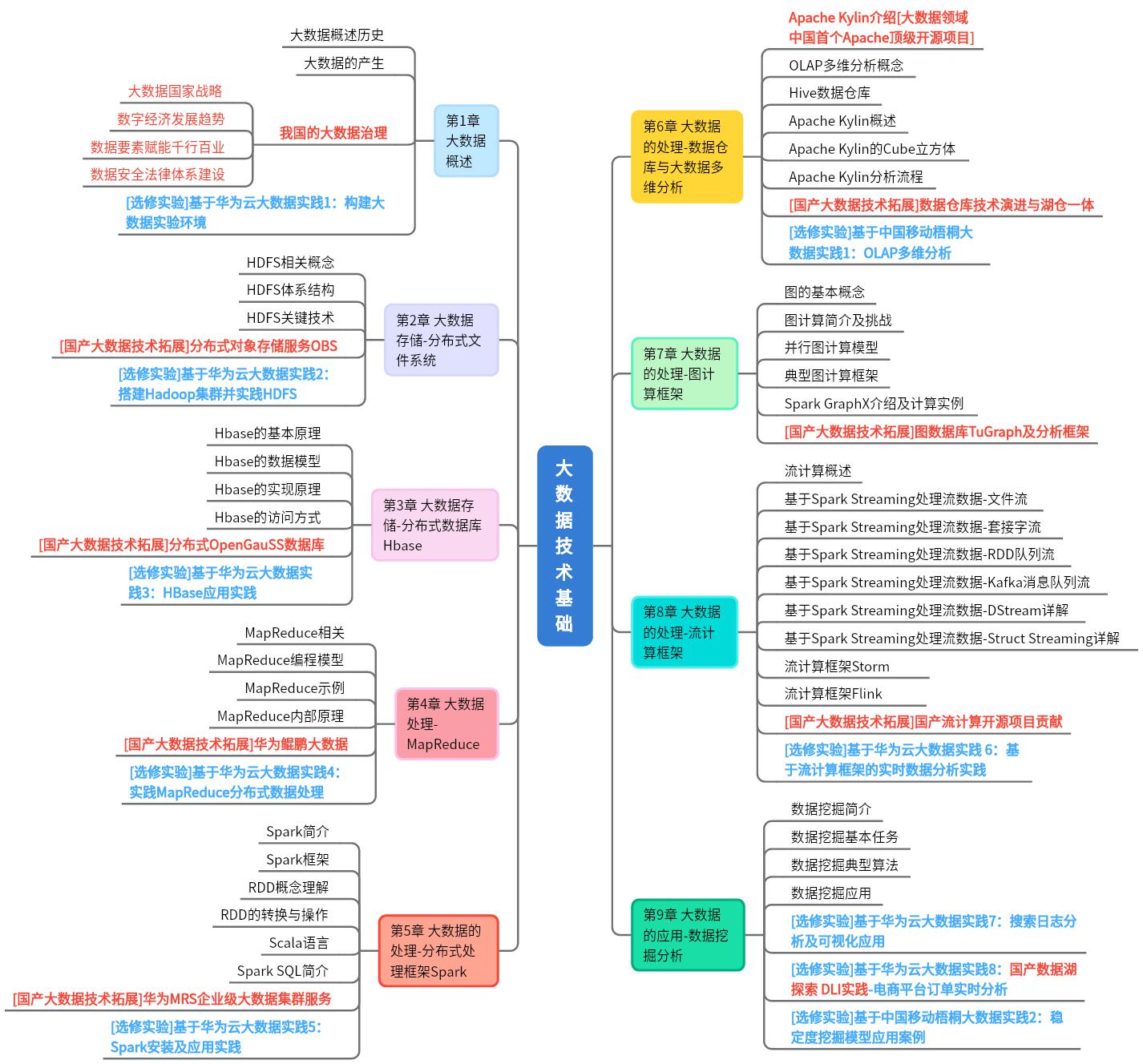
课程坚持核心价值引领,建立学生的大数据观。通过讲述“技术跟跑、技术并跑、技术领跑”三个阶段的中国大数据自主技术研发历程和“产业基础夯实、产业链建立、产业生态培育”三个方面的中国大数据自主产业发展案例,引导学生逐步树立创新思维与攻坚精神,认识理解“走中国特色大数据自主创新之路,以数字中国建设推进中国式现代化”的深刻内涵,进一步树立家国情怀与报国信念。
课程坚持系统知识传授,建立学生的大系统观。通过教授大数据思维概述、采集存储、处理计算、分析、可视化应用大数据五大知识模块,帮助学生充分理解和系统掌握大数据全生命周期的技术原理;结合通信、电商、金融、营销、社会服务大数据五大应用场景,帮助学生直观感受和真切体会大数据赋能千行百业的数据价值,培养学生形成数据生命周期系统观。
课程坚持工程能力培养,建立学生的大工程观。通过组织华为云鲲鹏大数据基础实验、中国移动梧桐大数据综合实训、创新创业实践的“实验×实训×实践”三步提升,结合“企业专家引进来”和“学校学生走出去”,阶梯培养学生的基础实验操作能力、复杂问题求解能力和科学创新创造能力,培育学生拥有坚持不懈大工匠精神。

图中为课程的实验和实训案例内容(持续更新中)。课程旨在让学生了解和掌握大数据技术知识,能够采用科学有效的方法,合理地选择基于大数据技术的开发工具和资源,进行大数据系统的设计、开发、验证以及数据分析与结果评价,进而解决计算机和大数据应用领域的复杂工程问题。
1.1 大数据概述
1.2 我国的大数据治理
[基础实验]华为云鲲鹏大数据基础实验体系1:构建大数据实验环境
第二章 大数据存储-分布式文件系统
2.1 HDFS相关概念
2.2 HDFS体系结构
2.3 HDFS关键技术
[基础实验]华为云鲲鹏大数据基础实验体系2:搭建Hadoop集群并实践HDFS
第三章 大数据存储-分布式数据库Hbase
3.1 Hbase的基本原理
3.2 Hbase的数据模型
3.3 Hbase的实现原理
3.4 Hbase的访问方式
[基础实验]华为云鲲鹏大数据基础实验体系3:HBase应用实践
第四章 大数据处理-MapReduce
4.1 MapReduce相关
4.2 MapReduce编程模型
4.3 MapReduce示例
4.4 MapReduce内部原理
[基础实验]华为云鲲鹏大数据基础实验体系4:实践MapReduce分布式数据处理
第五章 大数据的处理-分布式处理框架Spark
5.1 Spark简介
5.2 Spark框架
5.3 RDD概念理解
5.4 RDD的转换与操作
5.5 Scala语言
5.6 Spark SQL简介
[基础实验]华为云鲲鹏大数据基础实验体系5:Spark安装及应用实践
第六章 大数据的处理-数据仓库与大数据多维分析
6.1 Apache Kylin出现背景
6.2 OLAP多维分析概念
6.3 Hive数据仓库
6.4 Apache Kylin概述
6.5 Apache Kylin的Cube立方体
6.6 Apache Kylin分析流程
[综合实训]中国移动梧桐大数据综合实训体系1:大数据交互式OLAP多维分析实践
第七章 大数据的处理-图计算框架
7.1 图的基本概念
7.2 图计算简介及挑战
7.3 并行图计算模型
7.4 典型图计算框架
7.5 Spark GraphX介绍及计算实例
第八章 大数据的处理-流计算框架
8.1 流计算概述
8.2 基于Spark Streaming处理流数据-文件流
8.3 基于Spark Streaming处理流数据-套接字流(网络IO流)
8.4 基于Spark Streaming处理流数据-RDD队列流
8.5 基于Spark Streaming处理流数据-Kafka消息队列流
8.6 基于Spark Streaming处理流数据-DStream详解
8.7 基于Spark Streaming处理流数据-Struct Streaming详解
8.8 流计算框架Storm介绍
8.9 流计算框架Flink介绍
[基础实验]华为云鲲鹏大数据基础实验体系6:基于流计算框架的实时数据分析实践
第九章 大数据的应用-数据挖掘分析
9.1 数据挖掘简介
9.2 数据挖掘基本任务
9.3 数据挖掘典型算法
9.4 数据挖掘应用
[基础实验]华为云鲲鹏大数据基础实验体系7:搜索日志分析及可视化应用
[基础实验]华为云鲲鹏大数据基础实验体系8:综合实践-电商平台订单实时分析
[综合实训]中国移动梧桐大数据综合实训体系2:金融行业“羊毛党”用户识别案例实践
[综合实训]中国移动梧桐大数据综合实训体系3:高速道路及服务区拥堵洞察案例实践
[综合实训]中国移动梧桐大数据综合实训体系4:大数据可视化——以务工人员可视化分析为例
期末考试